YOLOv5是一個基於YOLO(You Only Look Once)架構的物體檢測開源項目。由Ultralytics公司開發並在GitHub上發布,YOLOv5以其高效、準確和易用性而聞名。本文將詳細介紹YOLOv5,包括其架構、特性、使用場景和主要功能。
YOLOv5架構
YOLOv5繼承了YOLO系列的高效物體檢測理念,並進一步在模型架構上進行了優化。YOLOv5主要由以下幾個部分組成:
- Backbone(骨幹網絡):
YOLOv5的骨幹網絡負責提取圖像的基本特徵。YOLOv5使用了CSP(Cross Stage Partial Networks)架構作為骨幹網絡,這種架構能夠有效地平衡計算成本和檢測精度。CSP通過在每個階段引入部分連接,減少了重複計算,從而提升了網絡的效率。 - Neck(頸部網絡):
頸部網絡用於進一步處理和融合特徵圖。YOLOv5使用了PANet(Path Aggregation Network)結構來增強特徵融合的能力。PANet通過融合不同層次的特徵圖,提高了對物體的檢測精度,特別是在小物體檢測方面。 - Head(頭部網絡):
頭部網絡負責最終的物體檢測和分類。YOLOv5的頭部網絡基於YOLO架構進行設計,包含多個預測層,每個層次負責不同大小的物體檢測。這種多尺度檢測方式使YOLOv5在各種場景中都能保持良好的性能。
YOLOv5特性
YOLOv5相較於前幾代YOLO模型,具有以下特性:
- 高效性:
YOLOv5在保持高檢測精度的同時,顯著提升了推理速度。這主要歸功於CSP和PANet等高效架構的應用,使模型能夠在有限的計算資源下實現高性能。 - 輕量化:
YOLOv5提供了多個模型變體,包括YOLOv5s(small)、YOLOv5m(medium)、YOLOv5l(large)和YOLOv5x(extra large),用戶可以根據實際需求選擇合適的模型。這些模型在不同的計算資源和應用場景下都能夠靈活運用。 - 易用性:
YOLOv5在易用性方面進行了大量優化。Ultralytics提供了詳細的文檔、示例和教程,使開發者能夠輕鬆上手並進行自定義開發。此外,YOLOv5的代碼結構清晰、模塊化程度高,便於擴展和修改。 - 多功能性:
YOLOv5支持多種物體檢測任務,包括圖像分類、物體檢測和實例分割等。這使得YOLOv5成為一個功能強大的多用途工具,可以應用於廣泛的計算機視覺任務。
使用場景
YOLOv5可以應用於多種場景,包括但不限於:
- 監控系統:
在視頻監控系統中,YOLOv5可以用於實時檢測和追踪特定目標,如行人、車輛等,提高安全性和監控效率。 - 自動駕駛:
在自動駕駛技術中,YOLOv5可以用於檢測道路上的各種物體,如行人、車輛、交通標誌等,為自動駕駛系統提供精確的環境感知能力。 - 醫療影像:
在醫療領域,YOLOv5可以用於分析醫療影像,檢測特定病變或病灶,如腫瘤檢測、肺炎檢測等,輔助醫生進行診斷。 - 零售業:
在零售行業中,YOLOv5可以用於智能貨架管理、顧客行為分析等,提高運營效率和顧客服務質量。 - 農業:
在農業應用中,YOLOv5可以用於植物病蟲害檢測、農作物生長狀況監測等,幫助農民提高農業生產效率。
主要功能
YOLOv5具備豐富的功能,支持各種物體檢測需求。以下是YOLOv5的一些主要功能:
- 多尺度檢測:
YOLOv5通過多個預測層進行多尺度檢測,能夠同時檢測不同大小的物體,提高了檢測的全面性和準確性。 - 數據增強:
YOLOv5內置了多種數據增強技術,如隨機裁剪、隨機翻轉、顏色變換等,增強了模型的泛化能力,減少了過擬合風險。 - 自動錨框調整:
YOLOv5支持自動錨框調整功能,根據訓練數據自動生成最佳的錨框參數,提高檢測精度和效率。 - 模型剪枝和量化:
YOLOv5支持模型剪枝和量化技術,能夠在保持檢測性能的同時,顯著減少模型大小和計算成本,適合在資源受限的設備上運行。 - 實時推理:
YOLOv5具有高效的推理性能,能夠實現實時物體檢測,適用於各種需要即時響應的應用場景。 - 可視化工具:
YOLOv5提供了多種可視化工具,如檢測結果的可視化、訓練過程的可視化等,幫助用戶更好地理解和調試模型。 - 支持多種數據集:
YOLOv5支持多種常見的物體檢測數據集,如COCO、Pascal VOC等,並且用戶可以方便地使用自己的數據集進行訓練和測試。
YOLOv5安裝步驟
下面是YOLOv5在Windows上的安裝步驟:
1. 確認安裝必要的工具
在安裝YOLOv5之前,請確保已經安裝了以下工具:
- Python 3.8或更高版本
- Git
- CUDA(如果需要使用GPU加速)
2. 安裝Python和pip
如果你還沒有安裝Python,可以從Python官方網站下載並安裝Python。安裝過程中請選中“Add Python to PATH”選項。
安裝完成後,打開命令提示符(cmd)並輸入以下命令來確認安裝:
python --version
pip --version3. 安裝Git
從Git官方網站下載並安裝Git。安裝完成後,打開命令提示符並輸入以下命令來確認安裝:
git --version4. 克隆YOLOv5倉庫
打開命令提示符,使用以下命令克隆YOLOv5倉庫:
git clone https://github.com/ultralytics/yolov5.git
cd yolov55. 創建並激活虛擬環境
為了避免與系統中的其他Python包發生衝突,建議創建一個虛擬環境。使用以下命令創建並激活虛擬環境:
python -m venv venv
venv\Scripts\activate6. 安裝依賴包
在虛擬環境中,運行以下命令來安裝YOLOv5所需的依賴包:
pip install -r requirements.txt7. 驗證安裝
安裝完成後,可以通過運行以下命令來驗證YOLOv5是否已成功安裝:
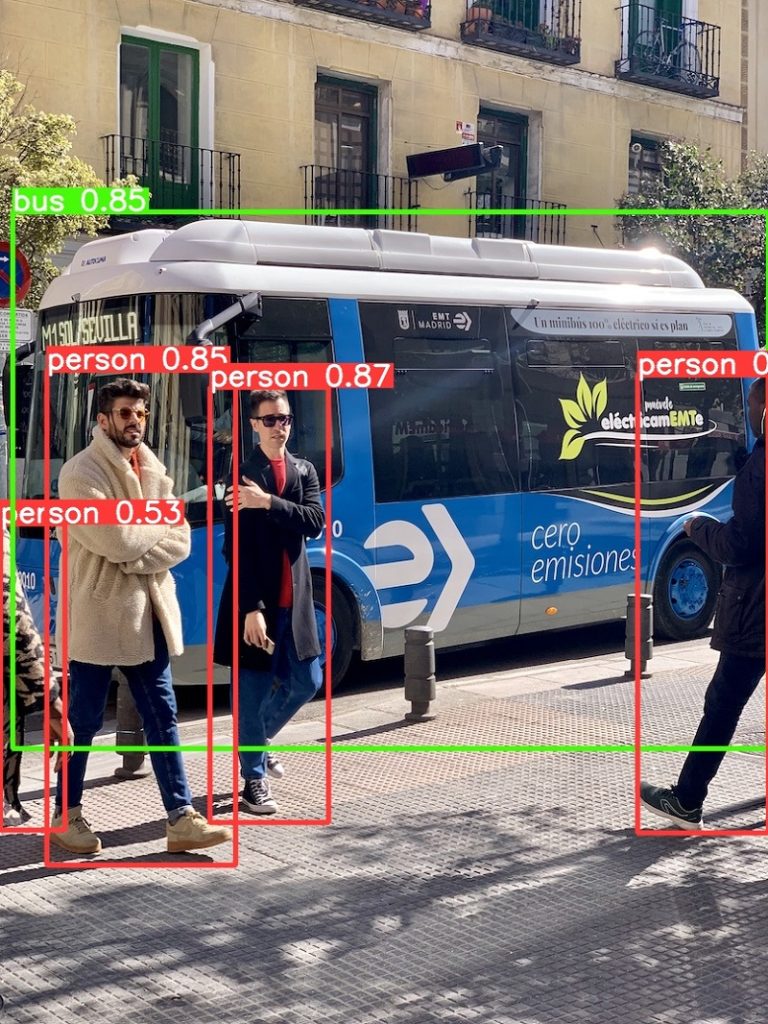
python detect.py --source data/images --weights yolov5s.pt --conf 0.25 --save-txt這將使用預訓練模型 yolov5s.pt 在 data/images 文件夾中的圖像上運行物體檢測,並將檢測結果保存到 runs/detect 目錄中。
8. 訓練自定義模型(可選)
如果你需要使用自定義數據集來訓練YOLOv5模型,可以按照以下步驟進行:
- 準備數據集:
- 準備好包含標註信息的數據集,標註格式應為YOLO格式(每行包括
class x_center y_center width height)。 - 創建一個數據集配置文件(如
data.yaml),定義訓練和驗證數據集的路徑,以及類別數和類別名稱。
- 準備好包含標註信息的數據集,標註格式應為YOLO格式(每行包括
- 開始訓練:
- 使用以下命令開始訓練自定義模型:
python train.py --data data.yaml --cfg models/yolov5s.yaml --weights '' --batch-size 16這將使用data.yaml文件中的數據集配置,並基於yolov5s.yaml模型配置文件進行訓練。 - 監控訓練過程:
- 在訓練過程中,可以通過
runs/train目錄中的文件來監控訓練過程,包括損失值、準確率和其他指標。
- 在訓練過程中,可以通過
如何使用YOLOv5訓練自訂義模型?
要使用YOLOv5訓練自訂義模型,首先需要準備好資料。這包括收集和標註圖像、組織資料夾結構、編寫資料配置文件。以下是詳細步驟:
1. 收集和標註圖像
首先,你需要準備要用於訓練的圖像並進行標註。YOLOv5使用YOLO格式的標註文件,每個圖像對應一個標註文件,格式如下:
class_id x_center y_center width heightclass_id:物體的類別ID(從0開始)。x_center:物體中心點的x座標,相對於圖像寬度的比例(0到1之間)。y_center:物體中心點的y座標,相對於圖像高度的比例(0到1之間)。width:物體的寬度,相對於圖像寬度的比例(0到1之間)。height:物體的高度,相對於圖像高度的比例(0到1之間)。
可以使用標註工具如LabelImg或Roboflow來標註圖像。
使用LabelImg進行標註
LabelImg是一款流行的開源圖像標註工具,支持YOLO格式的標註文件。以下是使用LabelImg進行標註的步驟:
- 安裝LabelImg 你可以通過以下命令安裝LabelImg:
pip install labelImg安裝完成後,可以通過以下命令啟動LabelImg:labelImg - 打開圖像資料夾 在LabelImg的界面中,點擊「Open Dir」按鈕,選擇包含要標註的圖像的資料夾。
- 設置標註格式 在LabelImg的界面中,點擊「YOLO」按鈕,將標註格式設置為YOLO格式。
- 開始標註圖像
- 使用「Create RectBox」工具(快捷鍵
W)在圖像上繪製矩形框來標註物體。 - 輸入物體的類別名稱。對於新類別,LabelImg會自動分配一個類別ID。
- 完成標註後,點擊「Save」按鈕(快捷鍵
Ctrl+S)保存標註文件。
- 使用「Create RectBox」工具(快捷鍵
- 重複標註 對資料夾中的所有圖像重複以上步驟,確保每個圖像都有對應的標註文件。
2. 組織資料夾結構
將標註好的圖像和標註文件按照以下結構組織:
/path/to/dataset/
├── images/
│ ├── train/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ ├── val/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
└── labels/
├── train/
│ ├── image1.txt
│ ├── image2.txt
│ └── ...
├── val/
│ ├── image1.txt
│ ├── image2.txt
│ └── ...images/train/:包含訓練圖像。images/val/:包含驗證圖像。labels/train/:包含與訓練圖像對應的標註文件。labels/val/:包含與驗證圖像對應的標註文件。
3. 編寫資料配置文件
在YOLOv5資料夾中創建一個資料配置文件(如data.yaml),內容如下:
train: /path/to/dataset/images/train
val: /path/to/dataset/images/val
nc: 2 # 類別數量
names: ['class1', 'class2'] # 類別名稱train:訓練圖像的路徑。val:驗證圖像的路徑。nc:類別數量。names:類別名稱列表。
4. 驗證資料準備
在YOLOv5資料夾中運行以下命令,檢查資料是否準備正確:
python train.py --img 640 --batch 16 --epochs 3 --data data.yaml --weights yolov5s.pt --cache這將加載資料並檢查其格式是否正確。運行成功後,會開始訓練過程。
開始訓練自訂義模型
確認資料準備正確後,可以開始訓練自訂義模型:
python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov5s.pt--img:輸入圖像大小,預設為640。--batch:批次大小,根據GPU顯存大小調整。--epochs:訓練回合數。--data:資料配置文件的路徑。--weights:預訓練權重文件的路徑,可以使用yolov5s.pt或自行訓練的模型。
訓練過程會生成模型權重文件,保存在runs/train/exp/weights目錄中。
以上步驟詳細介紹了如何準備資料以訓練YOLOv5自訂義模型,包括使用LabelImg進行標註。通過這些步驟,你可以組織資料、編寫配置文件並開始訓練,以獲得適合你應用場景的物體檢測模型。希望這些步驟能夠幫助你順利進行YOLOv5的自訂義模型訓練。
YOLOv5是一個功能強大且靈活的物體檢測框架,具有高效、準確、易用等特性。無論是在監控系統、自動駕駛、醫療影像還是零售業和農業中,YOLOv5都能夠提供優異的物體檢測能力。隨著深度學習技術的不斷發展,相信YOLOv5將在更多領域發揮其價值,推動計算機視覺技術的進步。